Overview of RAG
RAG (Retrieval-Augmented Generation) has become an essential component, alongside PEFT, in the development of GenAI (Large Language Model) systems. It is a technology designed to overcome the inherent limitations of standard LLM architectures. RAG enhances a model’s ability to provide accurate and contextually relevant answers by retrieving and referencing external documents during the response generation process.
For instance, users of ChatGPT may have noticed an hourglass icon appear when the system performs a web search—this process is powered by RAG. By integrating retrieval with generation, the model can access up-to-date and domain-specific knowledge that may not exist within its training data.
Moreover, RAG enables capabilities such as instantly providing users with the most relevant product information by retrieving documents containing details about affiliated companies’ offerings. This makes RAG a critical component in GenAI (LLM) applications, as it ensures precise, real-time responses—especially in specialized domains or when addressing the latest information.
Benefits of Building a RAG
- By understanding the architecture and workflow of RAG, one can recognize its advantage in securely storing sensitive data when providing GENSI (LLM) services. This aspect becomes a critical point for applying security controls and ensuring compliance.
- AI services such as OpenAI are composed of various RAG agents, and these industries recognize the importance of RAG in GenAI (LLM) services.
- RAG enhances the quality of response services by utilizing far more external knowledge sources than those contained within the parameters of an LLM.
- Research has shown that utilizing RAG can reduce hallucinations by providing factual, up-to-date, and accurate information.
- By leveraging various external knowledge sources, it gains the advantage of easily integrating and delivering new information as part of its service.
- By utilizing various RAG agents tailored to specific targets or purposes, it offers the advantage of efficiently and easily scaling large-scale knowledge.
- It enables continuous improvement of GenAI service quality through components such as retrieval, without the need to modify the LLM itself.
RAG Architecture and Components
A RAG system is composed of various technological elements that integrate traditional GenAI with search capabilities to deliver context-specific responses to queries. The following diagrams illustrate several examples that help in understanding the RAG architecture.
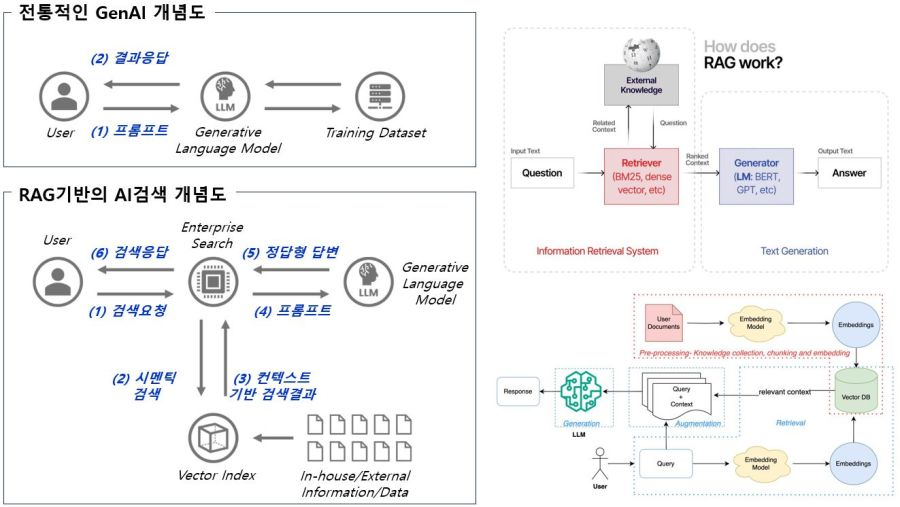
Although there are several types of architectures depending on the purpose, a typical RAG architecture consists of three tiers: Knowledge Source / Vector Database, Retriever, and Generator.
Knowlege Source/Vector Database(Documents/Databases, Indexing, Embedding Generation, Vector Database) ↔ Retriever(Fectch Relevant Contect) ↔ Generator(GEN, LLM, GPT, Claud)
Examining the workflow of the RAG architecture:
1) The knowledge source is indexed, and vector embeddings are generated and stored in the database.
2) For a given query, the retriever uses semantic search and Approximate Nearest Neighbor (ANN) algorithms to find the most relevant context from the database.
3) This context is then utilized by the LLM to generate the user’s response.
Tier-1: Knowlege Source/Vector Database
- Knowledge Source: A core component of the RAG system, consisting of text documents, databases, and knowledge graphs that collectively form a comprehensive knowledge base.
- ndexing / Embedding Generation: A component responsible for classifying information and creating indexes to enable efficient retrieval of data from the knowledge source.
- Vector Database: The generated embeddings are stored in a vector-optimized database, allowing for efficient similarity-based retrieval.
Tier-2: Retriever
- Retriever: The retriever uses semantic search and Approximate Nearest Neighbors (ANN) to fetch contextually relevant data from the vector database based on a given query or prompt. It goes beyond simple keyword matching by understanding the semantic meaning of the query to retrieve more accurate and meaningful information.
- Because the retriever plays a critical role in determining the overall performance of the RAG system, various techniques are employed—such as Multi-Query Retriever, Parent-Document Retriever, Self-Query Retriever, and Time-Weighted Retriever.
Tier-3: Generator
Generator: The generator is an LLM model such as GPT, LLaMA, or Claude, typically composed of open-source frameworks. It retrieves context from the retriever to generate and refine coherent, contextually relevant responses, which are then delivered to the user or system. In most cases, access to the generator is provided through APIs offered by the respective LLM platforms.
RAG as a Key Security Control Point in GenAI (LLM) Systems
RAG, which has become an essential component of GenAI (LLM) applications that retrieve external knowledge to respond to user requests, serves as a critical security control point in terms of information security and personal (credit) data protection when viewed through the lens of its architectural structure.
By applying information security measures within the RAG framework, organizations can achieve robust protection objectives through mechanisms such as data anonymization for external data, access control and encryption for vector databases, query validation, validation of generated content, and access control over output information.
Moreover, many of the vulnerability types identified in the OWASP Top 10 for LLM Applications, which represents the global security standard for GenAI (LLM) systems—such as LLM01: Prompt Injection, LLM02: Insecure Output Handling, LLM03: Training Data Poisoning, and LLM06: Sensitive Information Disclosure—are closely related to the RAG system architecture.
Tier-1: Knowledge Source / Vector Database – Risk Factors and Security Requirements
> Potential Risks
- If the vector database storing the knowledge sources is tampered with or compromised, the RAG system may utilize inaccurate data or become vulnerable to malicious retrieval-based attacks.
- Without proper access control measures for the vector database, malicious actors may gain unauthorized access, compromising both data integrity and personal information protection.
- The vast amount of stored knowledge may contain sensitive or proprietary information, and without proper data protection measures, there is a significant risk of data breaches.
- Because RAG systems depend on the vector database, an attacker who deliberately disrupts the database’s availability can cause problems across the entire RAG system.
Security Requirements
- Access Control for the Vector Database
mplement strong user authentication and authorization mechanisms to ensure that only authorized personnel can access the database. Even within the group of approved users, access levels should be carefully differentiated and managed based on specific roles and responsibilities. - Data Encryption
Apply encryption to both stored and transmitted data to ensure that, even in the event of unauthorized access, the information remains unreadable, thereby maintaining data protection. - Monitoring and Alerts
Continuously monitor all operations performed on the database to detect abnormal patterns. Implement real-time alerts to notify administrators of potential security incidents. - Backup and Recovery
Perform regular backups so that knowledge sources can be restored in case of corruption or loss. Ensure backups are securely protected and conduct routine integrity checks. - Query Rate Limiting
Implement rate limiting on database queries to prevent resource exhaustion and potential service disruption. This measure can also mitigate certain types of denial-of-service attacks. - Data Validation and Sanitization
Validate and sanitize data before it is ingested into the database to prevent injection attacks or the inclusion of malicious content. - Regular Security Assessments
Conduct periodic security vulnerability assessments to identify weaknesses and ensure adherence to current security best practices, thereby maintaining data security. - Network Security
Secure the network on which the vector database operates by deploying firewalls, intrusion detection/prevention systems, and isolating the database within protected network segments. - Patch Management
Continuously monitor and apply the latest patches from the vector database vendor to protect the database from known vulnerabilities.
Tier-2: Retriever Risk Factors and Security Requirements
Potential Risks
- Prompt Injection Risk
One of the fundamental security measures for a retriever is the validation of queries or prompts. This is particularly important in mitigating risks associated with rapid injection attacks on vector databases. Unlike traditional SQL or command injection attacks targeting conventional databases, prompt injection in vector databases may involve manipulating search queries to retrieve unauthorized or sensitive information. By strictly validating each prompt or query before processing, the system ensures that only legitimate requests are executed against the vector database, thereby preventing malicious actors from exploiting the retrieval process. - Unauthorized Data Access to the Vector Database
As noted above, unauthorized access to the vector database from the retriever tier can pose a risk to the entire RAG system. - Risks Related to the Similarity-Search Functionality of Vector Databases
There may be risks such as data leakage via similarity queries, manipulation of search results, reconnaissance and pattern analysis, and resource exhaustion.
Security Requirements
- Implementation of Query Validation Mechanisms
Thoroughly inspect each user query prior to processing. The primary purpose of query validation is to filter out potentially harmful or malicious queries that could exploit system vulnerabilities and to detect queries that may violate the organization’s data leakage prevention policies by attempting to exfiltrate internal data. - Access Control for the Vector Database
Access control for the vector database should go beyond simple user authentication and include comprehensive authorization management that defines who can search for what type of information. Access control must be detailed and differentiated to manage varying levels of permissions among users, which is essential in environments where different users have different authorization levels or where the system handles data with varying degrees of sensitivity. - Maintaining Data Integrity
Ensure that information retrieved from the vector database is not altered during the retrieval process. Applying encryption during data transmission helps maintain security and integrity. - Regular Audits and Monitoring
Conduct regular audits and continuous monitoring of the retrieval process to track all processed queries, analyze patterns that may indicate potential security threats, and detect unauthorized access attempts. Such proactive monitoring helps identify and mitigate potential threats quickly, before they can be exploited against system vulnerabilities.
Tier-3: Generator Risk Factors and Security Requirements
Potential Risks
- Incorrect or Misleading Content
LLMs may generate responses that are factually incorrect or misleading. Such erroneous outputs can lead to inaccurate or poor decision-making and may further propagate misinformation to a wider audience. - Biased or Offensive Content
Due to biased training data or the nature of a given query, LLMs inherently carry the risk of generating biased or offensive content. This can lead to defamation or legal liability, particularly when the generated content is discriminatory or violates content standards. - Data Privacy Violations
LLMs may inadvertently generate responses that contain or infer sensitive information, potentially leading to data privacy breaches. This risk is heightened when the model has been exposed to sensitive training data. - Output Manipulation
There is a risk of external manipulation in which an attacker adversely influences the LLM to generate specific responses through crafted queries or by exploiting vulnerabilities in the model. - Vulnerabilities in Automation and Repetitive Tasks
When LLMs are employed for automated workflows—such as through agentic tools like AutoGPT, BabyAGI, or the OpenAI Assistant API—they can be vulnerable to abuse, where repetitive or predictable responses may be maliciously exploited.
보안 요구사항
- Validation of Generated Content
Carefully examine responses produced by the LLM to identify and filter misleading, offensive, or inappropriate content. Auditing the validity of generated content is an essential safeguard—particularly when the information is widely disseminated or used for critical decision-making. - Integrity Checks for Generated Content
Verify that the LLM’s responses are consistent with the provided context to prevent the model from diverting to irrelevant or sensitive subjects. This is particularly important to maintain the relevance and appropriateness of outputs. - Protection of Training Data
When fine-tuning is involved in an RAG system for business requirements, give special attention to the training data used for the LLM. Ensuring that training data is fully anonymized reduces the risk that the model will inadvertently include or infer sensitive information in its responses, serving as a preventive measure against privacy breaches. - Monitor Queries and Inputs to the LLM
Detect attempts to manipulate outputs by submitting crafted queries or exploiting model weaknesses. Implement mechanisms to prevent data loss by ensuring that inputs and prompts do not contain sensitive data. - Bias Mitigation during Fine-Tuning
Ensuring diverse and representative datasets for fine-tuning can substantially reduce bias. Techniques such as removing bias from word embeddings can further refine the model’s neutrality. - Human-in-the-Loop Evaluation during Fine-Tuning
Consider employing human evaluators during fine-tuning to provide valuable insights and nuanced judgments, ensuring the model meets ethical and quality benchmarks. - Content Moderation Controls
Implement allowlists and blocklists during output generation to enforce content filtering according to predefined criteria. - Data Privacy during Fine-Tuning
Incorporate best practices such as privacy-preserving measures and data anonymization when fine-tuning the model. - Comprehensive Model Evaluation
After fine-tuning, subject the model to thorough evaluations of performance, safety, and quality standards. Establish governance measures—such as defined roles and responsibilities (R&R) and policies—to support this process. - Secure API Endpoints
Always use HTTPS for API endpoints to ensure encrypted data transmission and protect against eavesdropping. - API Rate Limiting
Consider implementing rate limits to defend against DDoS attacks and to ensure uninterrupted service availability. - Authentication and Authorization
Adopt robust authentication mechanisms (e.g., OAuth 2.0, JWT) combined with fine-grained authorization controls to ensure that users or systems can access only authorized resources. - API Input and Output Validation
Strictly validate and sanitize all API inputs to protect against injection attacks—one of the central concerns in OWASP Top 10. Because LLM inputs are natural language, input validation presents challenges; continuous monitoring and defense against evolving attack techniques are therefore required. - Secure Error Handling
Design error messages to avoid revealing information that could assist an attacker. Prevent disclosure of sensitive details to reduce the risk of information leakage. - Regular Updates and Patching
Regularly monitor and apply the latest patches provided by API vendors to protect against known security vulnerabilities. - API Logging and Monitoring
Maintain detailed logs of API access and implement real-time monitoring with alerts for suspicious activity. - API Dependency Review
A Software Bill of Materials (SBOM) and open-source vulnerability checks are essential. In particular, ML-related SBOMs follow different release cycles than traditional software SBOMs; therefore, regularly verify that all third-party libraries or dependencies used by APIs—especially those involving ML components—do not contain known vulnerabilities.
Summary of Our GenAI (LLM) Red Team Service
A summary of the GenAI (LLM) Red Team services we provide is as follows.
What is a GenAI (LLM) Red Team?
A GenAI (LLM) Red Team is a group tasked with identifying and testing security vulnerabilities in GenAI (LLM) services such as LLMs and RAG. The LLM Red Team conducts simulated adversarial attacks within the field of cybersecurity to identify weaknesses in LLM services and to recommend remediation and improvement measures.
GenAI(LLM) Red Team Activity
– RAG and LLM application penetration testing (LLM-specialized pentest, vulnerability identification, and security hardening recommendations)
– Generation of ML-SBOM (AI-SBOM) and vulnerability scanning (if required)
– Establishment of LLM governance and management frameworks (policies, guidelines) (if required)
Expected Benefits of the GenAI (LLM) Red Team Service
Based on global security assessment criteria, evaluate the security vulnerabilities of LLM services that companies or institutions are developing or operating, thereby strengthening security and the protection of personal (including credit) information.
Techniques & Tools
– LLM vulnerability scanner (proprietary automated tool)
– ML (AI)-SBOM generator (proprietary automated tool)
– Consulting for establishment of LLM policies, guidelines, and governance
– Manual assessments based on consultants’ experience and expertise
Deliverables
– LLM penetration test report
– ML (AI)-SBOM and vulnerability findings report
– LLM governance implementation report (if required)
– LLM application vulnerability assessment report (if required)