OWASP Top 10 for LLM Application
LLM01. Prompt Injection
Malicious users may manipulate the LLM (GenAI) to redefine system prompts or induce unintended actions through external inputs, leading to data leakage or social engineering attacks.
LLM02. Insecure Output Handling
If the outputs generated by the LLM (GenAI) are not properly validated, vulnerabilities such as XSS, CSRF, or SSRF may occur.
LLM03. Training Data Poisoning
Security, effectiveness, or ethical behavior can be compromised if the LLM (GenAI) is trained or fine-tuned with malicious data.
LLM04. Model Denial of Service
Attackers may repeatedly trigger resource-intensive tasks in the LLM (GenAI), degrading service performance and availability.
LLM05. Supply Chain Vulnerabilities
Security risks may arise from vulnerabilities in externally sourced training data, plugins, or other dependencies.
LLM06. Sensitive Information Disclosure
There is a risk that the LLM (GenAI) may expose sensitive information during responses.
LLM07. Insecure Plugin Design
Insecurely designed LLM (GenAI) plugins (Platform-to-Plugin or Plugin-to-Plugin) that accept unsafe inputs may result in remote code execution or similar exploits.
LLM08. Excessive Agency
LLM (GenAI)-based systems that are granted excessive functionality or authority may behave unpredictably or perform unintended actions.
LLM09. Overreliance
Excessive dependence on LLM (GenAI) may lead to the spread of incorrect information, legal issues, or the introduction of security vulnerabilities.
LLM10. Model Theft
Malicious actors may gain unauthorized access to, copy, or exfiltrate LLM (GenAI) models, resulting in potential economic losses.
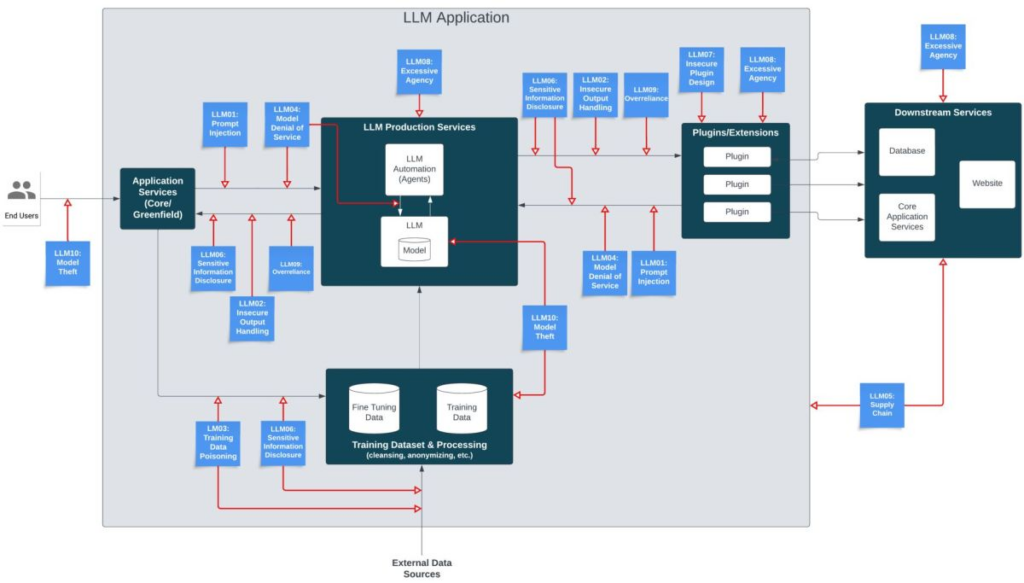
LLM Application Data Flow Diagram
The diagram below is a high-level architecture of a hypothetical large language model (LLM) application, highlighting the risk areas where the OWASP Top 10 for LLM Applications intersect with the application flow. This diagram serves as a visual guide to help understand how LLM security risks impact the overall application ecosystem.
LLM 01. Prompt Injection (프롬프트 주입)
Description
A prompt injection vulnerability occurs when an attacker manipulates input to control an LLM so that it unwittingly executes the attacker’s intent. This can be done directly by overriding the system prompt via “jailbreaking” (or “DAN”) or indirectly by tampering with external input, and may lead to data exfiltration, social-engineering attacks, and similar problems. The results of a successful prompt injection attack vary widely — from extracting sensitive information to masquerading as normal operation and influencing critical decision-making. In high-level attacks, an adversary can manipulate the LLM to impersonate a malicious persona or to interact with plugins in the user’s settings, which can cause sensitive data leaks, unauthorized plugin actions, or social engineering. In such cases, the compromised LLM can act as the attacker’s agent, bypass security controls, and prevent users from noticing the intrusion.
Common Examples of Vulnerability
Direct Prompt Injection: Also called “jailbreaking” (or “DAN”), this occurs when a malicious user overwrites or reveals the system prompt to manipulate the LLM. Through this, the LLM can interact with insecure functions and data stores it has access to, allowing abuse of backend systems.
Indirect Prompt Injection: This occurs when an LLM accepts input from external sources. An attacker inserts prompt injection into external content such as a website or file to hijack the conversational context. This enables the LLM to act as a “confused agent,” manipulating users or additional systems. Indirect prompt injection can succeed whether or not a human can read the content—if the LLM can parse the text, it is possible. A malicious actor can perform prompt injection directly on the LLM, causing it to ignore the application creator’s system prompt and instead return private, dangerous, or undesired information. For example: a user asks the LLM to summarize a webpage that contains indirect prompt injection; the LLM may be led to elicit sensitive information from the user and exfiltrate it via JavaScript or Markdown. A malicious actor uploads a resume containing indirect prompt injection; the document instructs the LLM to tell the user the document is excellent. If an internal user runs the LLM to summarize this document, the LLM’s output will state that the document is excellent. If a user enables a plugin connected to an e-commerce site, malicious commands embedded in a visited website can exploit that plugin to trigger unauthorized purchases. Malicious commands and content on visited sites can likewise exploit other plugins to deceive users.
LLM 02. Insecure Output Handling (안전하지 않은 출력처리)
Description
Insecure output handling refers to cases where the output generated by an LLM is not properly validated, sanitized, or processed before being passed on to other components or systems.
Since the content generated by an LLM can be influenced by prompt input, this is similar to allowing a user indirect access to additional functionalities.
Insecure output handling concerns how the LLM’s output is managed before it is transferred to other systems, and is distinct from general issues of the LLM’s accuracy or appropriateness.
Common Examples of Vulnerability
If an application instructs an LLM to query a database based on user input, failure to properly review the LLM’s output can lead to attacks such as SQL injection.
When JavaScript or Markdown generated by the LLM is executed in a browser, insufficient output validation can result in XSS (Cross-Site Scripting) attacks.
If the LLM takes user input and executes commands in a system shell, inadequate review of the LLM’s output can lead to remote code execution.
LLM 03. Training Data Poisoning (학습 데이터 포이즈닝)
Description
Training data is the starting point for all machine learning approaches. For an LLM to achieve high capability (e.g., language and world knowledge), that text must span diverse domains, genres, and languages. LLMs use deep neural networks that generate outputs based on patterns learned from the training data.
Training data poisoning involves manipulating the data used in pre-training, fine-tuning, or embedding processes to introduce vulnerabilities, backdoors, or biases that can undermine the model’s security, effectiveness, or ethical behavior.
Poisoned information can be exposed to users or cause risks such as degraded performance, downstream software abuse, and reputational damage. Even if users do not trust problematic AI outputs, the model’s functionality can be impaired and the brand’s reputation harmed.
Common Examples of Vulnerability
Malicious actors or competitors generate malicious or inaccurate documents targeting the model’s pre-training data, fine-tuning data, or embeddings.
The compromised model learns the false information, which is then reflected in the outputs of generative AI prompts.
LLM 04. Model Denial of Service (모델 서비스 거부)
Description
A denial-of-service (DoS) attack on a model occurs when an attacker interacts with an LLM in a way that consumes excessive resources, leading to degraded service quality for other users or incurring high resource costs.
Additionally, attacks that disrupt or manipulate the LLM’s context window have emerged as a significant security issue. This becomes even more critical as LLMs are increasingly used in various applications, consume large amounts of resources, accept unpredictable user input, and as developers often lack awareness of such vulnerabilities.
In an LLM, the context window represents the maximum length of text the model can process, including both input and output, and its size varies depending on the model’s architecture.
Common Examples of Vulnerability
- Continuous input overflow: An attacker continuously sends inputs that exceed the LLM’s context window, causing the model to consume excessive computing resources.
- Repeated long inputs: An attacker repeatedly sends long inputs so that each input exceeds the context window.
- Recursive context expansion: An attacker crafts inputs that cause the LLM to recursively expand and process the context window, consuming excessive compute resources.
- Variable-length input flood: An attacker overwhelms the LLM by sending a large number of inputs of varying lengths up to the context-window limit. This exploits inefficiencies in handling variable-length inputs to overload the model and render it unresponsive.
LLM 05. Supply Chain Vulnerabilities (공급망 취약점)
Description
The supply chain of an LLM may contain vulnerabilities that can affect the integrity of training data, machine learning models, and deployment platforms. Such vulnerabilities can lead to biased results, security breaches, or failures across the entire system. Traditionally, vulnerabilities have focused on software components, but in machine learning, third-party pretrained models and training data are also susceptible to poisoning and tampering attacks.
Finally, LLM plugin extensions can introduce their own vulnerabilities. These issues are covered in detail in LLM07 – Unsafe Plugin Design.
Common Examples of Vulnerability
- Traditional third-party package vulnerabilities: use of outdated or no-longer-supported components.
- Use of vulnerable pretrained models: models used for fine-tuning that have vulnerabilities.
- Use of poisoned crowdsourced data: training data that has been poisoned.
- Use of unmaintained models: security issues arising from using models that are no longer supported.
- Unclear terms and data-privacy policies: the model operator’s terms may be vague, creating a risk that an application’s sensitive data could be used for model training and later exposed. This also applies to the risk of model providers using copyrighted material.
LLM 06. Sensitive Information Disclosure (민감한 정보 노출)
Description
LLM applications can expose sensitive information, specific algorithms, or other confidential details in their outputs. This can lead to unauthorized access to sensitive data, intellectual property infringement, privacy violations, and other security breaches. Users of LLM applications should be aware of the risk that sensitive data they unknowingly submit may later appear in outputs. To mitigate these risks, LLM applications must perform adequate data sanitization to ensure users’ data are not included in the model’s training data. Owners of LLM applications should provide clear terms of use so users understand how their data are handled and offer options that allow users to opt out of having their data included in model training. Interactions between users and LLM applications form a two-way trust boundary. Because data sent from the client to the LLM or returned from the LLM to the client cannot be inherently trusted, this vulnerability assumes that threat modeling, infrastructure security, and appropriate sandboxing are outside its scope. Adding restrictions within the system prompt on the types of data the LLM may return can partially mitigate sensitive-data leakage, but due to the LLM’s unpredictable nature such restrictions are not always enforced and can be bypassed via prompt injection or other vectors.
Common Examples of Vulnerability
- Failure to fully or properly filter sensitive information in LLM responses.
- Sensitive data overfitted or memorized during the training process.
- Confidential information unintentionally exposed due to LLM misinterpretation, lack of data sanitization methods, or data-handling errors.
LLM 07. Insecure Plugin Design
Description
Unsafe plugin design refers to security issues that occur when an LLM interacts with faulty or malicious plugins. Such plugins can expand the attack surface of the LLM application, allowing unauthorized access to sensitive data or the execution of malicious actions. While plugins provide additional functionality, if they are not properly reviewed or secured, they can compromise the security of the entire system. The security of unsafe plugin design should be considered in two contexts: LLM Application-to-Plugin and Plugin-to-Plugin interactions.
Common Examples of Vulnerability
- Unauthorized data access: when a plugin collects or transmits sensitive data externally without the user’s consent.
- Command injection: when improper input validation allows the plugin to execute system commands.
- Privilege escalation: when a plugin operates with unintended privileges, compromising the system or data.
- Insecure communication: when data transmitted between the plugin and the server is unencrypted, allowing eavesdropping or tampering.
- Insecure updates: when a plugin downloads updates from unverified sources, potentially introducing malicious code.
LLM 08. Excessive Agency
Description
Excessive agency refers to situations where an LLM is given too much authority or autonomy. This can allow the LLM to act beyond the user’s intent or the system’s safety boundaries, creating security risks. Excessive agency is particularly problematic when the LLM is able to execute system commands or interact with external systems.
Common Examples of Vulnerability
- Command execution: when the LLM can directly execute system commands, leading to the execution of malicious instructions.
- External system interaction: when the LLM interacts with external APIs or services, causing unintended consequences.
- Data modification: when the LLM can directly alter data in a database or file system, resulting in data corruption or leakage.
- Automated decision-making: when the LLM autonomously makes critical decisions, potentially causing system or business damage due to incorrect judgments.
LLM 09. Overreliance
Description
Excessive reliance refers to issues that arise from depending too heavily on an LLM. This occurs when users or systems place too much trust in the LLM’s outputs, accepting its judgments or results uncritically. Such overreliance can lead to misinformation, legal issues, and security vulnerabilities.
Common Examples of Vulnerability
- Misinformation: when users accept inaccurate or incorrect information generated by the LLM as fact and use it for decision-making.
- Legal issues: when content generated by the LLM infringes copyrights or leads to legal complications.
- Security vulnerabilities: when the LLM’s output is applied to systems without validation, resulting in security weaknesses.
- Unethical use: when the LLM’s output contains unethical or biased content, causing social or ethical problems.
LLM 10. Model Theft
Description
Model theft refers to actions in which an attacker unlawfully accesses or copies an LLM’s confidential information or intellectual property. This can cause economic loss, reduced competitiveness, and security breaches for the model owner. Model theft can be carried out in various ways and becomes likely if appropriate security measures are not in place. An attacker can query the API with adversarial inputs and collect enough outputs to create a shadow model (a model that imitates the original model’s structure or data and behaves similarly). To extract data from the original model, an attacker may proceed with: (a) observing model inputs and outputs, (b) collecting data and training a shadow model, and (c) using the shadow model to predict the original model’s behavior as part of the attack.
Common Examples of Vulnerability
- Model API abuse: when an attacker steals a model API key and uses the model without authorization.
- Model replication: when an attacker trains a similar model using the original model’s outputs to replicate it.
- Model file leakage: when model files are exposed externally due to an insider’s mistake or malicious action.
- Cloud infrastructure compromise: when attackers exploit security vulnerabilities in cloud infrastructure to access model files.